

für Entscheidungsträger: Insgesamt ist der Prozess der Bestellung eines Cheeseburgers ein komplexes Zusammenspiel von linguistischer Semantik, sozialen Normen und kulturellen Erwartungen, das darauf abzielt, eine erfolgreiche Transaktion zwischen dem Kunden und dem Restaurantpersonal zu erleichtern. Die Kunst, einen Cheeseburger zu bestellen, gleicht einem komplexen Tanz zwischen sprachlichen Akrobatikern, sozialen Fallstricken und der Suche nach der perfekten Portion Glückseligkeit, die zwischen zwei Brötchenhälften liegt. Man muss die Sprache der Speisekarten entschlüsseln, die versteckten Codes von „bitte“ und „danke“ beherrschen, während man so cool wie eine Gurke bleibt, um den Respekt des Restaurantpersonals zu verdienen. Es ist eine Reise voller Herausforderungen, aber wenn es gelingt, einen Cheeseburger zu bestellen, ist es nicht nur eine Mahlzeit – es ist ein epischer Triumph über kulinarische Strömungen!
👨🍳 (Semantische) Zutaten
Was in Midjourney (geschlossener Quellcode, siehe unten) zu den Ziel-Promptschlüsseln wie F.R.A.M.E., S.S.S.C.L.A. oder F.O.C.A.L. führt, ist COSTAR in GPT4: Kontext: die Hintergrundinformationen, Ziel: das Ziel, auf das sich das LLM konzentrieren soll, Stil: Schreibstil, Ton: Einstellung der Antwort, Publikum: der beabsichtigte Empfänger, Antwort: Format der Antwort. (Für über die Semantik hinausgehende Aspekte empfehle ich diesen Artikel.) Um nicht als voreingenommen zu gelten, möchte ich auch einige Open-Source-lizenzierte Alternativen hier vorstellen: Render Net, Realistic Vision, Absolute Reality, RealVisXL, Epic Realism, NextPhoto, CyberRealistic, NightVisionXL.
Übrigens, in Bezug auf meinen letzten Beitrag zu den neuen konsistenten Charakteren von Midjourney gibt es einen interessanten Beitrag zu Multi-Charakter-Konsistenz und Charakter-Vermischung auf @HalimAlrasihi.
A1) 100% Freiland oder Bio Stall-Rindfleisch – Fundamentmodelle
(siehe hiezu mein Blog, kopie-von-midjourneyii, Textgeneratoren); [Selbstredend bezieht sich länderspezifisch alles auf die US-Marktdominanz dieser Technologie (in China ist Open-AI dominierend).]
| Das Geschäft des Schreibens von Fundamentmodellens (LLMs) | |
| versehen mit dem Markenzeichen von | |
| Offene KI | Geschlossene KI |
| Firma OpenAI (chat GPT – Sam Altman), Microsoft (+LinkedIn), Musk (Twitter/X-xAI/SpaceX) | Gemini (ex-Bard = Google), Meta AI (Zuckerberg), Claude |
| Chat GPT (mitbegründet von Musk im Jahr 2015, der 2018 aus dem Vorstand ausschied) war ursprünglich eine Non-Profit-Organisation, ist mittlerweile jedoch gewinnorientiert – also nicht mehr so „Offene KI“ Das größte Modell, GPT-4, zeichnet sich dadurch aus, dass seine Parameteranzahl mehr als 170 Billionen beträgt. ChatGPT4 befähigt die KI von Microsoft Bing. Musks Grok basiert auf GPT-3.5, wobei Grok-1 LLM 63 Milliarden Parameter hat. | |
Grok an sich ist kein Fundament-LLM, also was qualifiziert Grok-1 als LLM? Grok ist ein generatives Modell (siehe unten) und eine LLM-Anwendung, sozusagen eine App in Denglish. Die Ära der LLMs ist jedoch vorbei, aber das hindert OpenAI nicht daran, GPT-5 zu entwickeln (Potenzial für den Status einer AGI (Künstliche Allgemeine Intelligenz, AGI-Systeme wären in der Lage, eigenständig zu lernen, Probleme zu lösen und sich in verschiedenen Umgebungen anzupassen, ähnlich wie ein menschliches Gehirn.), siehe auch unten Göttliche Nachrichten nachstehend).
Musk gegen Altman ist ein Streit über LLM-Anwendungen und gleichzeitig ein Meuterei in Bezug auf die horizontale und vertikale KI-„Bounty“ (siehe a) und b) unten). Nun, für das Groken in Österreich benötigen Sie vorerst dies, um überhaupt einen Bezug zu dem Streit zu haben.
🌋Göttliche Nachrichten: AGI (self-controlled AI), das Q-Projekt
🚀 19/03/2024: Der xAI Open Sources Grok-1 Quellcode wird veröffentlicht (kostenloser Download auf GitHub ohne Lizenzgebühren, Benutzer können jetzt darauf aufbauen). Mit diesem Schritt kann und muss nun jedes Land der Welt eine Meinung zu dem Streit haben.
- Grok AI, ein 314 Billion Parameter (zu Deutsch 314 mit 12 Nullen) umfassendes Modell, wird als offener Quellcode freigegeben (siehe die 63 in der linken Spalte oben – es passiert rasend schnell).
- Lizenziert unter der Apache-Lizenz 2.0 für kommerzielle Nutzung.
- Es ist kein Schulungscode in der Veröffentlichung enthalten.
- Grok-1 wurde auf einem maßgeschneiderten Stapel trainiert. (Anmerkung: wage, wage, meine Lieben)
- Das Potenzial für die Nutzung von Gesprächssuche durch Perplexity AI (gehandelt als die neue Google-Suche, das Schweizer Taschenmesser. Aber keine Panik, Google bleibt bestehen.).
- Elon Musk kritisiert (nicht mehr so) OpenAI und strebt an, die Ideale der gemeinnützigen KI aufrechtzuerhalten.
💸Note: Musk‘s neue Lizenz Implementation darf ja auch mit Spannung erwartet werden.
A2) RINDFLEISCH FÜR DUMMERLN – Fundamentmodelle für Dummerln. Jede/r, der ein Haushaltsbuch geführt hat oder führt, kann nun verstehen, was Fundamentmodelle sind. Alles, was Sie brauchen, ist eine Tabelle. Setzen Sie sich also bitte hin, entspannen Sie sich und betrachten Sie die Tabelle/Tabellenkalkulation (bitte die Kurz-Übungen für den Aha-Moment anschauen). Der Oscar für ELI5 (Erklär es mir als ob ich Fünf wäre) geht an
B) Gewürze, Essiggurken, Tomaten, Beilagen und Saucen – DIE DIENSTLEISTUNGEN, DIE AUF DEN FUNDAMENTMODELLEN VERKAUFT WERDEN a) vertikale und b) horizontale Dienstleistungen
Wortschatz:
- SaaS – Software als Service
- Horizontale SaaS ist eine Art Cloud-Softwarelösung, die auf eine breite Zielgruppe von Geschäftsanwendern abzielt, unabhängig von ihrer Branche.
- Vertikale SaaS-Lösungen umfassen Software, die auf eine spezifische Nische oder branchenspezifische Standards abzielt. Dies ist ein aktueller Trend in der Entwicklung des SaaS-Marktes. Da vertikale Software speziell für klare Branchennischen konzipiert ist, begrenzt sie die Größe des potenziellen Marktes.
- On-Top-SaaS: Gezielte und/oder branchenneutrale Software, die entwickelt wurde, um mit einer vorhandenen Lösung oder mehreren Lösungen zu integrieren (z. B. Zapier). Zu diesem Zweck haben Marken begonnen, proprietäre Software-Ökosysteme aufzubauen, die als PaaS (Platform as a Service) bekannt sind. Durch die Verwendung von PaaS-Plattformen können SaaS-Unternehmen neue Produkte entwickeln, die ihnen helfen, in spezifische Branchen einzusteigen, während sie neben einer konsolidierten Marke arbeiten.
- Gewürze und Saucen/Generative Modelle: Generative KI, kurz für Generative Künstliche Intelligenz, ist in der Lage, Inhalte zu generieren, die ähnlich sind wie die Daten, mit denen sie trainiert wurde – von Texten über Bilder bis hin zu Musik. Das Potenzial ist beeindruckend, aber generative KI wirft auch Herausforderungen und ethische Bedenken auf, insbesondere im Hinblick auf die Authentizität und möglichen Missbrauch der generierten Inhalte. Generative KI-Modelle verwenden ein spezifisches neuronales Netzwerk, um neue Inhalte zu generieren. Je nach Anwendung gehören dazu: a) Generative Adversarial (gegensätzliche) Networks (GANs): GANs bestehen aus einem Generator und einem Diskriminator und werden häufig verwendet, um realistische Bilder zu erzeugen.Rekurrente Neuronale Netze (RNNs): RNNs sind speziell für die Verarbeitung sequenzieller Daten wie Text konzipiert und werden zur Erzeugung von Text oder Musik verwendet. c) Transformer-basierte Modelle: Modelle wie GPT (Generative Pretrained Transformer) von OpenAI sind Transformer-basierte Modelle, die zur Textgenerierung verwendet werden (Transformer News). d) Flussbasierte Modelle: Werden in fortgeschrittenen Anwendungen verwendet, um Bilder oder andere Daten zu erzeugen. e) Variationale Autoencoder (VAEs): VAEs werden häufig in der Bild- und Textgenerierung eingesetzt.
a) Vertikal – Rohmodelle (Link)
Zum Beispiel: Ein Unternehmen sucht Kandidatenmodelle für seine vertikale Branche oder Problemart oder beides auf einem Marktplatz und führt einige A/B-Tests durch. Sobald das Modell ausgewählt ist, würde es auf einen begrenzten Korpus von Daten ausgerichtet sein. Zum Beispiel könnte ein Sprachmodell, das zur Zusammenfassung von Transaktionen, Texten, E-Mails und Verträgen für Verstöße gegen Compliance verwendet wird, Daten anvisieren, die vollständig innerhalb der Grenzen des Unternehmens enthalten sind und in einigen Fällen möglicherweise mit ausgewählten Datensätzen aus Datenmärkten ergänzt werden. Diese Daten würden wahrscheinlich als Vektor-Embeddings (numerische Darstellung von Datenobjekten) gespeichert und über spezialisierte Vektorindizes zugänglich gemacht werden, die in spezialisierten Vektordatenbanken oder den Vektordatenspeichern der betrieblichen Datenbanken, die sie bereits verwenden, vorhanden sind. Im Gegenzug würden Sprachmuster und Terminologie auf viel engere Vokabulare und Ontologien trainiert werden.
Mainstream-Unternehmen sind nicht wie OpenAI oder ähnliche Unternehmen. Sie sind nicht darauf spezialisiert, Grundlagenmodelle zu erstellen, und sie verbrennen kein Risikokapital, um sie zu trainieren. Sie sollten keinen Zugang zu Zehntausenden von Grafikprozessoren benötigen. Aber um Halluzinationen vorzubeugen und sich auf ihre eigenen Probleme sowie ihre Ontologien und Terminologien zu konzentrieren, ist es klüger, die von ihnen implementierten Modelle nicht auf der ganzen Internetdatenmenge zu trainieren. Stattdessen werden sie das Training wahrscheinlich auf ihre eigenen Datensätze beschränken und optional relevante Datensätze von Drittanbietern aus Datenmärkten, sei es reale oder synthetische Datensätze, hinzufügen und diese durch abrufgestützte Generierung, oder RAG (retrieval-augmented generation), aktualisieren und relevant halten. Wenn es um Sprachmodelle geht, die speziell für das Geschäft trainiert sind, werden die Bescheidenen (kleinere domänenspezifische Modelle) eher Erfolg haben. Wir sprechen davon, Modelle auf Millionen statt Milliarden von Parametern zu trainieren.
Unternehmen müssen die Anwendungsfälle identifizieren und herausfinden, wie sie Governance-, Bias- und Urheberrechtsfragen angehen können. Wir werden hier nicht ausführlich auf Governance eingehen, aber das Problem ist viel undurchsichtiger und die Risiken (insbesondere bei Deepfakes, Urheberrechten und Sicherheit) sind breiter und tiefer als das, worüber wir bei „klassischen“ Machine-Learning-Modellen gesprochen haben. In der Zwischenzeit muss die Branche das Ökosystem und die Sicherheitsvorkehrungen zusammenstellen.
Aber das wird nicht über Nacht passieren. Es wird wahrscheinlich mindestens ein paar Jahre dauern, bis wir eine kritische Masse an domänenspezifischen Modellen sehen (obwohl sie hinsichtlich des Verkehrs bereits weitgehend angewendet werden) und bewährte Verfahren für ihre Dimensionierung entwickelt haben, um eine signifikante Wirkung zu erzielen. Aber es wird passieren.
b) Horizontale Dienstleistungen
werden als vorgefertigte Software-as-a-Service-Anwendungen bereitgestellt, die zu den Kosten angeboten werden, die Unternehmen tragen können. Ähnlich wie beim maschinellen Lernen zuvor werden für die meisten Unternehmen KI-Anwendungen als Anwendungen und nicht als Rohmodelle erscheinen.
Die bedeutendste Entwicklung wird hin zu KI-Modellen gehen, die sich unauffällig im Hintergrund halten. Sie werden in horizontalen Diensten eingebettet sein, wie z. B. Dokumentenaggregation, BI- und Visualisierungstools, sowie in Unternehmensanwendungen, die wir bereits von bekannten Marken wie Adobe Inc., Salesforce Inc., Zoom Video Communications Inc., etc. kennen. Microsoft Copilot für Office 365 ist wohl das prominenteste Flaggschiff, während SAP Joule die Arten von aufgabenbezogenen Co-Piloten verkörpert (dieser für die Optimierung der Arbeitskräfte), die wir in Unternehmensanwendungen sehen werden. Dies ähnelt dem, wie wir gesehen haben, wie Hintergrund-Maschinenlernen im Laufe der Jahre prädiktive Analysen in Unternehmensanwendungen wie Oracle Fusion Analytics unterstützt hat.
Das gemeinsame Merkmal ist, dass Unternehmen keine umfangreiche Schulung von Modellen benötigen, da diese als vorgefertigte Software-as-a-Service-Anwendungen bereitgestellt werden.
Von Spätherbst 2023 bis zum neuen Jahr wurde der Markt für Desktop-Benutzer mit spezifischen Anwendungen überschwemmt. Jetzt ist der Mobilmarkt dran, es ist unglaublich, wie kreativ man seit Jahresbeginn mit dem Handy sein kann.
Gen AI wird als die führende aufkommende Technologie der nächsten drei bis fünf Jahre angesehen. Und damit kommen hohe Erwartungen an wirtschaftliche Auswirkungen. Wie Sie wahrscheinlich schon am Klang erkennen können, ist generative KI der Zweig der künstlichen Intelligenz, der sich darauf konzentriert, neuen Inhalt in Form von menschenähnlichem Text, Bildern, Videos, Antworten auf Fragen, Stimmen, sogar Zeilen von Code zu erstellen.
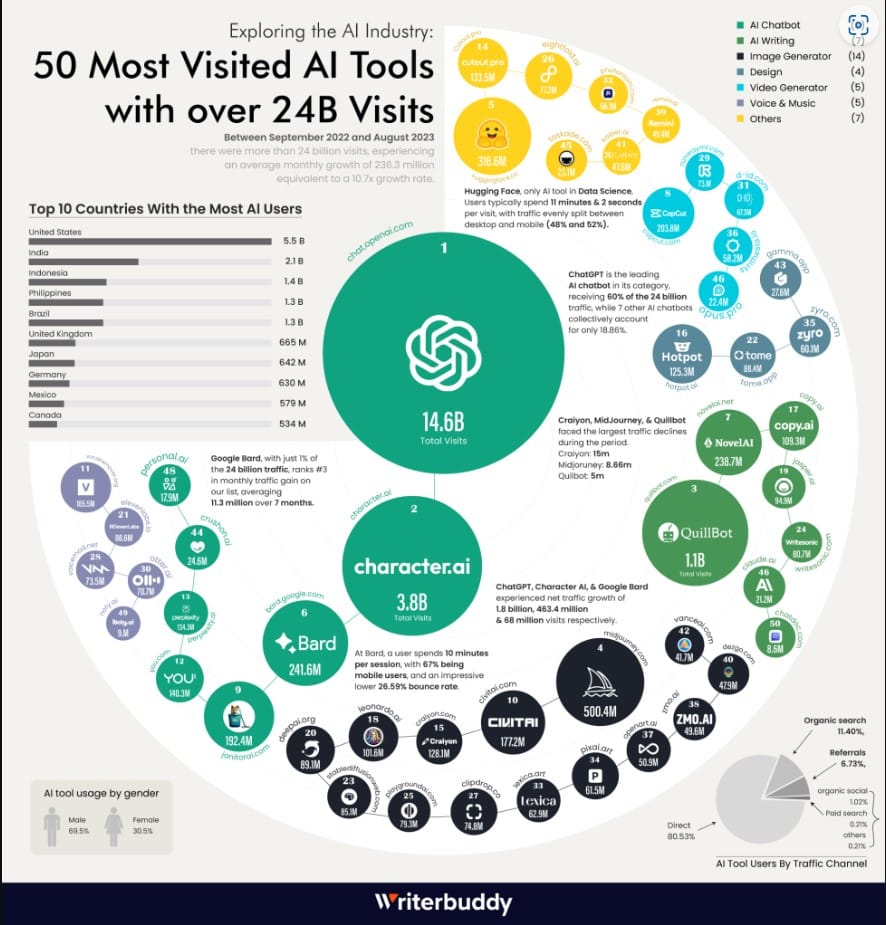
Es gibt eine Reihe von Bedenken im Zusammenhang mit der Verwendung von Generative KI. Neben der Qualität des generierten Inhalts betreffen diese auch die Möglichkeit des Missbrauchs.
- Missbrauch und Desinformation: Die Fähigkeit der generativen KI, realistischen Inhalt zu produzieren, kann missbraucht werden, z. B. für Deepfakes, Fake News, fiktive Dokumente und andere Formen von Fehlinformationen.
- Urheberrecht und geistiges Eigentum: Generierter Inhalt wirft Fragen des Urheberrechts und des geistigen Eigentums auf, da oft unklar ist, wer die Rechte an dem generierten Inhalt besitzt und wie er verwendet werden darf.
- Vorurteile und Diskriminierung: Wenn eine Generative Künstliche Intelligenz auf voreingenommenen Daten trainiert wurde, können sich diese in dem generierten Inhalt widerspiegeln.
- Ethik: Das Erstellen von falschem Inhalt und manipulierten Informationen kann ethische Fragen aufwerfen.
- Rechts- und Regulierungsfragen: Die rasche Entwicklung der generativen KI hat zu einer unklaren rechtlichen Situation geführt; es besteht Unsicherheit darüber, wie die Technologie reguliert werden sollte.
- Datenschutz und Privatsphäre: Die Verwendung von Generative KI zur Generierung personenbezogener Daten oder zur Identifizierung von Personen in Bildern ist im Hinblick auf Datenschutz und Privatsphäre fragwürdig.
- Sicherheit: Generative KI kann für Social-Engineering-Angriffe verwendet werden, die effektiver sind als menschliche Angriffe.
🏞🌄🌅 Gabriele2500 Panorama:
Zum einen haben wir hier in dieser Region der Welt im April 2024 keine totale Sonnenfinsternis; unsere nächste partielle Sonnenfinsternis ist im März 2025 und die nächste totale ist für 2081 geplant.
Was die Wahlpräferenzen betrifft, muss ich sagen, dass es nicht meine Wahl ist, aber wir haben auch dieses Jahr eine. Ich dachte über die USA nach und kam zu dem Schluss, mich zu fragen, wer seine Jeans am besten trägt, in dem Wissen, dass so lange Amerikaner nach Komfort, Stil und Selbstausdruck suchen, die zeitlose Liebesgeschichte zwischen Amerika und Jeans über Generationen hinweg bestehen wird. Und innerhalb dieses Narrativs/dieser Erzählung von Mode und Freiheit gibt es für mich einen unbestrittenen, aber kontroversen Champion, der nahtlos Sport, Komfort und Stil vereint. Was Österreich betrifft, ist die Antwort nicht so einfach. Jeder Kandidat sieht ziemlich ordentlich in ihren/seinen Jeans aus. Aber wie würde ihr Stil aussehen, wenn sie ihren eigenen politischen Stil als Mode tragen müssten? Aufgrund des Mangels an Interesse der Kandidaten, sich meiner Mode-Herausforderung zu stellen, beschränkt sich meine Auswahl der Kandidaten auf maximal 2. Tatsächlich habe ich bereits unumstößlich meine Wahl getroffen.
Thematisch relevante Trendnachrichten: Call me Datty

Persönlich stehe ich derzeit vor einigen Herausforderungen – wie immer – darunter die Bestimmung des Namens dieser Figur. Der Charakter basiert auf Queen Mousette aus den Blues Brothers, nur dass sie das Universum singen lässt. Nicht dass das sowieso nicht der Fall wäre, die Erde soll der G-Ton sein, den wir nur nicht hören können.

Bis dahin werde ich mich mit einem kleinen Kuchen trösten. Vergessen Sie nicht, dass zu Ostern die Glocken nach Rom fliegen und frohe Feiertage. 🐇 🐤 🐣 🧺 🌷 🦋 ❤️





Hinterlasse einen Kommentar